CB Audit (internal AEO/SEO tool) · Day 27 · May 27, 2026 · 10 min read
Building CB Audit — an agentic AEO + SEO report engine on Claude + OpenAI
Shipped CB Audit: a local, two-pipeline audit engine that drops a URL, crawls the site, generates buyer-intent queries with Claude, probes Claude + OpenAI, scores brand presence with a Claude-as-judge rubric, and renders branded HTML/PDF reports — plus a parallel classical-SEO pipeline. One web UI, one shared queue, ~$1–2 and 3–6 minutes per audit.
By Andy D — Founder, Creative Brain Inc. — Brampton, Ontario
The chooser at /. One tool, two questions: "Why isn't AI mentioning us?" (AEO)
and "Why aren't we ranking?" (SEO). Both pipelines share the queue, history, and progress stream.
TL;DR
- Shipped CB Audit — a local Node.js engine that turns a single URL into a branded AEO and SEO report, internal + client variants, HTML + PDF + CSV.
- The AEO pipeline crawls the site, has Claude generate 20 brand-neutral buyer-intent queries, probes both Claude (
claude-opus-4-7) and OpenAI (gpt-4o), then uses Claude as a judge to score every response on mention, position, citation, sentiment, framing, and competitor share-of-voice (0–100 composite). - The SEO pipeline runs a multi-page BFS crawl and scores seven weighted categories — technical, on-page, schema, Core Web Vitals (PageSpeed), links, LLM-judged content, and an optional competitor compare.
- A single Express + SSE server runs audits one-at-a-time off a file-backed queue, streams live progress, and survives restarts (in-flight jobs reconcile to
failedon boot). - Real numbers from the first runs: creativebrain.ca scored SEO 64/100; sprint.creativebrain.ca scored AEO 0 across 31 probes while Toptal/Bubble/Webflow ate the share-of-voice. The zero is the point — it's the baseline the cbinc-www work is now moving.
Wiring: pure Node, ESM, file-backed job store (data/jobs.json). Two idempotent migrations run on boot. No database. Keys via .env (ANTHROPIC_API_KEY, OPENAI_API_KEY, optional PAGESPEED_API_KEY).
Why we shipped this
The May 26 cbinc-www sprint log opens with "the May 5 audit gave us SEO 64 / AEO 1." Those numbers didn't come from Ahrefs — they came from this tool. CB Audit is the instrument we use to decide what to ship on our own site and, increasingly, in client pitches.
The motivating problem: AEO is a discipline you can't improve without measuring, and nothing off-the-shelf measures it. Classical SEO tools tell you about backlinks and Core Web Vitals. None of them answer the question a prospect actually triggers when they open ChatGPT or Claude and type "best 14-day MVP development services for startups" — does our brand even get named, and if so, are we the leader or the afterthought? The only honest way to measure that is to ask the real models the real questions and grade the answers.
So the AEO pipeline is deliberately empirical: it doesn't infer presence from on-page signals, it probes the live LLMs and scores what comes back. Buyer-intent queries are generated brand-neutral on purpose — if we seeded the brand name into the query, we'd measure nothing but the model's ability to echo. We want the organic mention rate.
The SEO pipeline rides along in the same tool for one practical reason: client pitches. Dropping one URL and getting both "here's how you rank" and "here's how you show up in AI" — as two branded PDFs — is the deliverable. Building them as two pipelines behind one queue meant the web UI, history, progress streaming, and report plumbing got written once.
Files added or modified
AEO pipeline (src/)
src/crawl.js— single-page fetch + Cheerio extraction: title, meta, headings, JSON-LD schema inventory, FAQ detection, content sample, brand guess.src/generate-queries.js— Claude generates 20 buyer-intent queries across 5 categories (category, comparison, problem-solution, brand, longtail).src/probe-llms.js— fans every query out to Claude + OpenAI with a shared system prompt,p-limitconcurrency, per-call error capture.src/score.js— Claude-as-judge scoring against the rubric, plusaggregate()for overall score, share-of-voice, per-provider and per-category breakdowns.src/recommend.js,src/report.js,src/run-pipeline.js— tiered recommendations, HTML/PDF render, AEO orchestrator.
SEO pipeline (src/seo/)
crawl.js— multi-page crawler (robots.txt, sitemap, BFS to N pages).audit-technical.js,audit-onpage.js,audit-schema.js,audit-performance.js(PageSpeed Insights),audit-links.js,audit-content.js(LLM keyword + content-quality),audit-competitors.js.score.js— weighted composite.recommend.js,remediate.js(paste-ready titles/meta/JSON-LD),report.js,run-pipeline.js.
Shared, server, and UI
src/dispatcher.js— kind-aware dispatcher; mapskind: "aeo" | "seo"to its pipeline and step list.src/shared/http.js,src/shared/pdf.js(Puppeteer launcher),src/shared/csv.js.server.js— Express + SSE, file-backed job store, single-job queue withpump(), report/CSV endpoints.web/app.js,web/index.html,web/styles.css— vanilla SPA chooser + forms + history + live results.run-audit.js,run-seo-audit.js— CLI entry points.
Prompts, templates, migrations
prompts/query-generation.md,prompts/scoring-rubric.md,prompts/recommendations.md+prompts/seo/*.templates/report.html,templates/report-client.html+templates/seo/*.scripts/migrate-add-kind.mjs,scripts/migrate-aeo-folders.mjs— idempotent, run on boot, back updata/jobs.jsonbefore mutating.
Design rationale
Two pipelines, one UI, one queue
AEO and SEO answer different questions, so they're different pipelines — but they share everything operational. The server doesn't know or care which pipeline a job runs; src/dispatcher.js takes the job's kind and returns the right orchestrator and step list. The web UI is a single chooser that branches into two forms, and both feed the same POST /api/audits.
The AEO entry. Competitors are optional — left blank, Claude infers 3–5 likely ones from the crawl context so share-of-voice still has something to measure against.
The SEO entry. Same shell, different inputs: full competitor URLs (not names) and a pages-to-crawl budget that caps the BFS crawl.
The rejected alternative was two separate apps. That would have doubled the queue, the SSE plumbing, the history table, and the report endpoints. Routing on a kind discriminator kept all of that single-sourced.
Claude plays three roles, and they're kept separate
Claude isn't called once — it's called as a query strategist (generate buyer-intent queries), as a respondent (one of the two probed models), and as a judge (score every response against the rubric). Each role has its own prompt file in prompts/ so the judge's rubric can evolve without touching the strategist's instructions. Treating "the model that answers" and "the model that grades" as distinct steps is what makes the AEO score defensible — the judge sees only the query, the response, the target brand, and the competitor list, and returns structured JSON.
The scoring rubric is the heart of it: every probe gets graded on mentioned + position (first / early / middle / late), cited, sentiment, framing (leader / alternative / afterthought / competitor_to_others), competitors_mentioned, and a 0–100 overall_score.
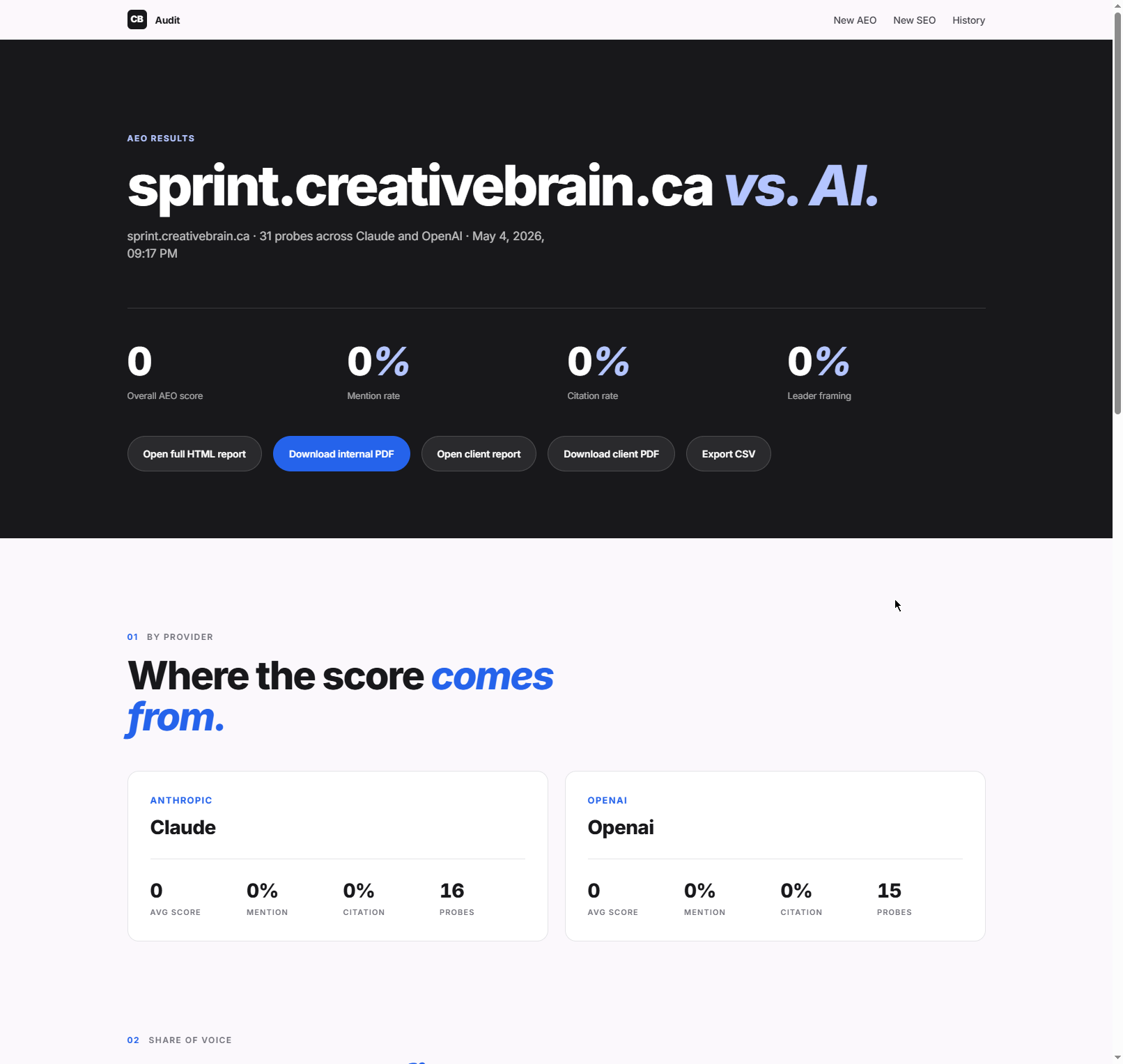
The headline metrics, split by provider. aggregate() in src/score.js
rolls the per-probe JSON up into overall score, mention/citation rates, framing distribution,
and the Claude-vs-OpenAI breakdown.
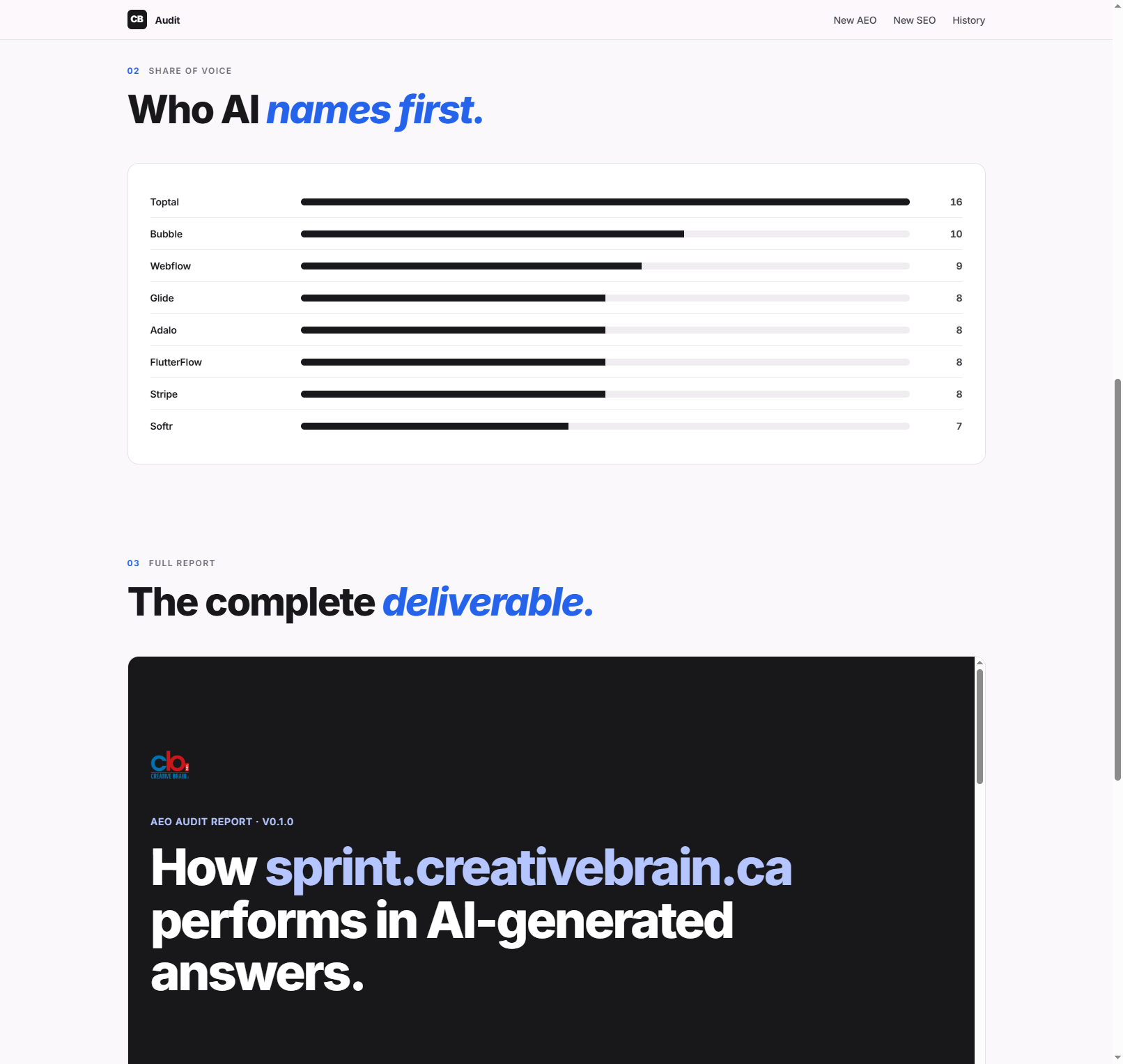
Share-of-voice is the slide that lands in pitches: when AI answers buyer questions in our category, these are the names it reaches for. Zero of them are us — yet.
SEO score is a weighted composite, not a vibe
The SEO pipeline produces a 0–100 score, but the number is only useful because it decomposes. Each category carries an explicit weight (technical 20% / on-page 20% / schema 10% / performance 15% / links 10% / content 20% / competitors 5%), so a single headline score always traces back to which category dragged it down. On creativebrain.ca that was Content (34/100) and Performance (50/100) pulling a 64 overall, while Schema sat at 100.
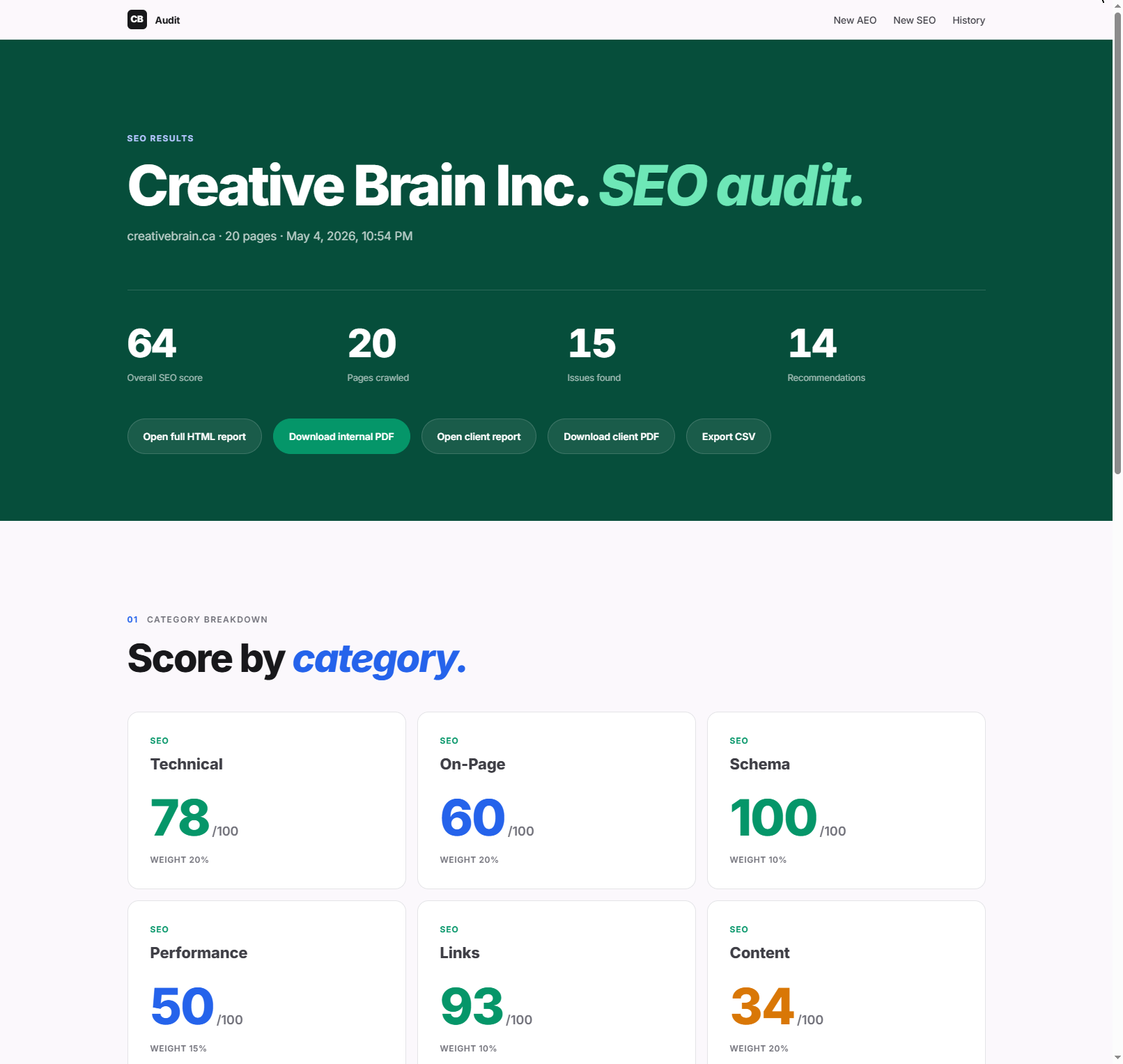
The category breakdown makes the composite honest — you can see exactly where the 64 comes from and which weight each category carries.
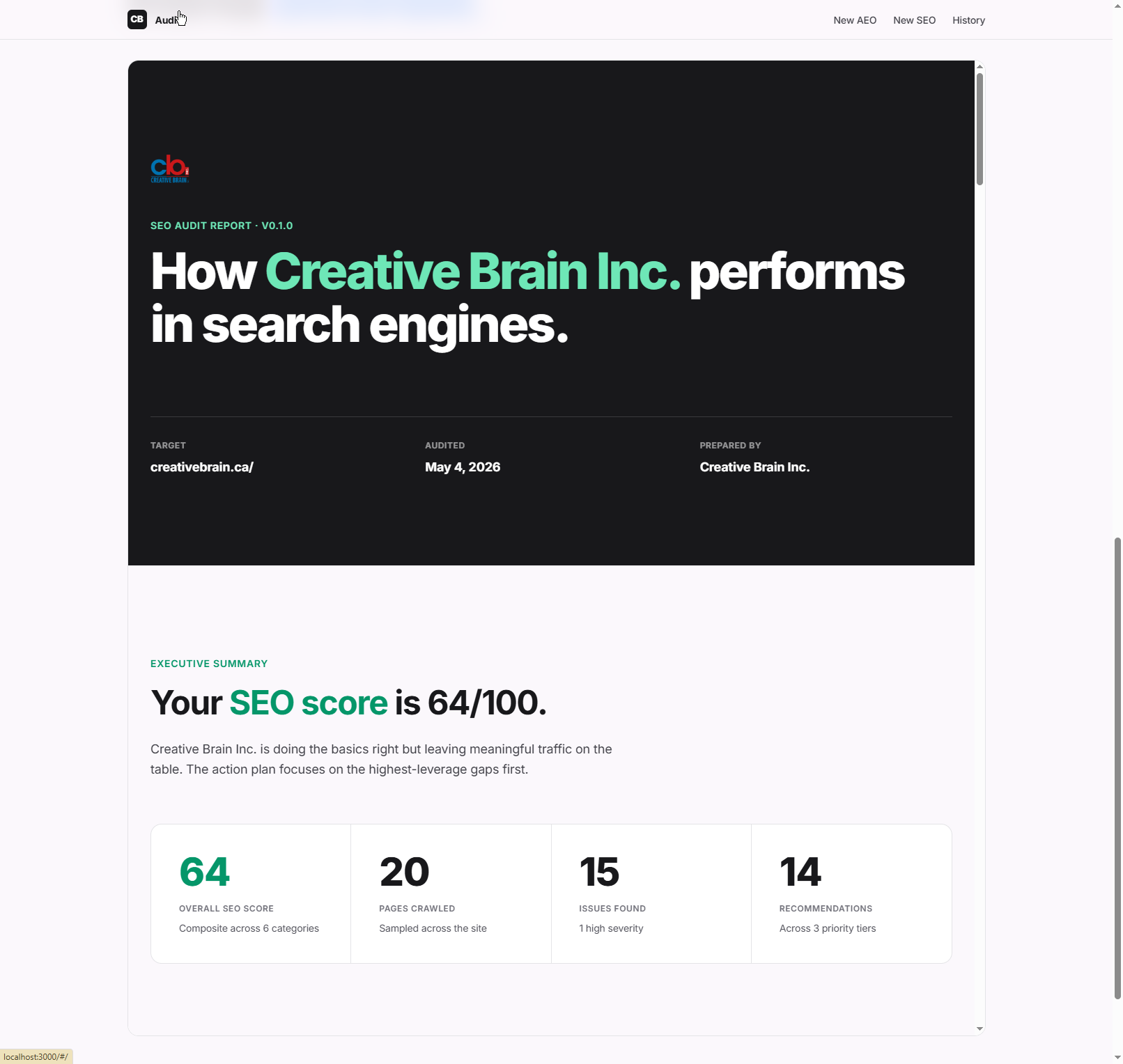
The full deliverable — the same data rendered as the client-facing report (HTML here, identical layout exported to PDF via Puppeteer).
File-backed queue over a job library
The server runs one audit at a time off an in-memory queue, persisting job state to data/jobs.json. No Redis, no BullMQ, no SQLite. For a single-operator local tool that runs a handful of audits a day, a JSON file plus a pump() function that starts the next job when the active one finishes is the right amount of machinery. The trade-off — no parallelism across audits — is acceptable because each audit is rate-limited against the model APIs anyway.
Gotchas we hit (so the next log doesn't repeat them)
-
LLMs fence their JSON even when told not to. Both
generate-queries.jsandscore.jsask for raw JSON with "no markdown fences," and the models wrap it in a```jsonblock anyway often enough to breakJSON.parse. Fix: strip fences before parsing —text.replace(/```json|```/g, '').trim()— rather than trusting the instruction. -
One flaky provider call shouldn't kill a 40-call run.
probeClaude/probeOpenAInever throw; they return{ error }objects, andaggregate()filters to valid results only. Carry-forward: in fan-out probe steps, capture per-call errors as data and exclude them at aggregation — don't letPromise.allreject the whole batch. -
A server restart used to strand jobs in
running. On boot,server.jsreconciles any job still markedrunningorqueuedtofailedwitherror: "interrupted by server restart". Fix: treat the file-backed store as untrusted on startup and reconcile in-flight state before accepting new work. -
Legacy rows had no
kind. The AEO+SEO split added akinddiscriminator that olderjobs.jsonrows lacked.migrate-add-kind.mjstags themkind: "aeo"andmigrate-aeo-folders.mjsrelocates legacy files intodata/aeo/+reports/aeo/, rewriting the path fields so old reports still resolve. Both are idempotent and write a one-time backup. Carry-forward: ship the migration with the schema change and run it on boot, not as a manual step. -
Core Web Vitals is optional by design. The performance audit calls Google PageSpeed Insights, which needs
PAGESPEED_API_KEY. Without it the step is skipped gracefully rather than failing the run — so an SEO audit still completes on a fresh checkout with only the two LLM keys set.
Verifying the work
cd cb-aeo-audit
npm install
cp .env.example .env # fill ANTHROPIC_API_KEY, OPENAI_API_KEY (PAGESPEED_API_KEY optional)
# Web UI — choose AEO or SEO at http://localhost:3000
npm run web
# Or from the CLI:
npm run audit:aeo -- https://your-brand.com --competitors=Acme,Globex --queries=20
npm run audit:seo -- https://your-site.com --pages=20
Module smoke tests (each runs one step against a hard-coded URL):
npm run test-crawl # src/crawl.js
npm run test-queries # Claude query generation
npm run test-probe # Claude + OpenAI probe
npm run test-score # Claude-as-judge
Then open History and confirm completed jobs render with their score, an Open HTML report, and a downloadable PDF — for both kinds.
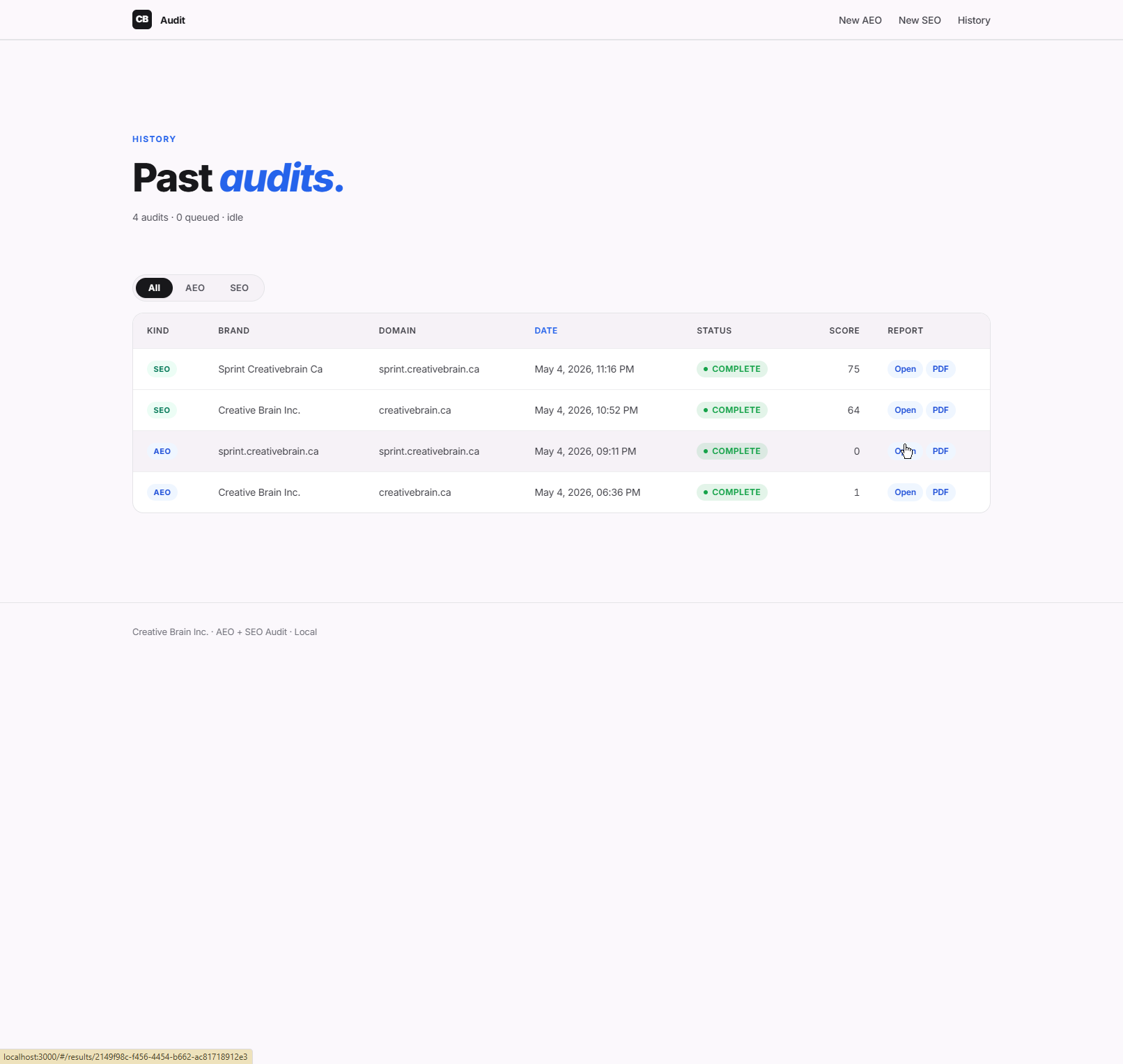
The shared history view — both pipelines write to one job table, filterable by kind. This is the quickest end-to-end check that the queue, scoring, and report endpoints all wired up correctly.
What's next
- Production re-audits, not localhost. Re-score creativebrain.ca and sprint.creativebrain.ca against the live deploy so HSTS, canonical, and trailing-slash artifacts drop out of the report — and so the AEO 0 baseline gets a real "after" number once the cbinc-www citable-surface work lands.
- More probe surfaces (deferred Phase 4). Add Perplexity and Gemini probes, scrape Google AI Overviews, and extract citation sources — right now share-of-voice is Claude + OpenAI only.
- Delta tracking. Persist each audit's aggregate so re-runs show movement over time per query and per competitor, instead of standalone snapshots.
- White-label PDF mode for client-delivered reports, and a combined
#/domain/:hostview that overlays a domain's AEO and SEO results on one page. - Scheduled re-audits + email digests — blocked on deciding where this runs (it's local-only today; a hosted scheduler is a separate build).